실 서비스의 모델배포에 있어 어려움을 겪어 경량화의 중요성에 대해 깨닫게 되었다.
이에 경량화 중 모델 압축 기법에 대해 공부해보고자 한다.
경량화 기법 중 Pruning, Quatization, Distillation에 관하여 공부해보았다.
경량화의 필요성
1) 높은 비용: 거대한 모델을 학습시키는 데는 엄청난 계산 자원이 필요하므로, 높은 경제적 비용이 발생함
2) 추론 비용: 추론 과정에서도 많은 계산 자원이 필요하므로, 실시간으로 빠른 응답이 요구되는 서비스에 모델을 적용하는 것을 어렵게 함
3) 접근성 문제: 거대한 모델은 모바일폰이나 임베디드 기기에서 활용불가
경량화의 종류

1) Pruning: 중요하지 않은 부분을 적절히 가지치기를 해서 줄일 것이냐
2) Quantization: 해상도를 낮춰서 작게 만들 것이냐
3) Distillation: 사이즈 자체를 작게 만들 것이냐
...
1. Pruning

개요
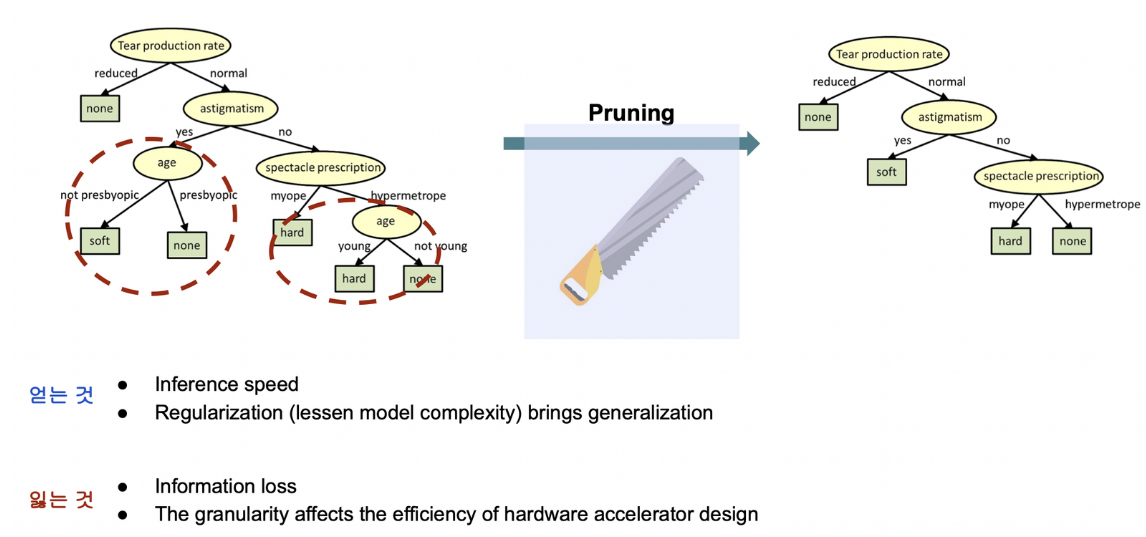
딥러닝 모델의 많은 레이어 중 중요하지 않은 파라미터를 지워 모델을 경량화하는 방법
Weighted Sum for Pruning
한 레이어에 존재하는 여러 파라미터의 중요도에 따라 다른 가중치를 적용하여 중요한 부분과 중요하지 않은 부분의 크기를 다르게 만듦
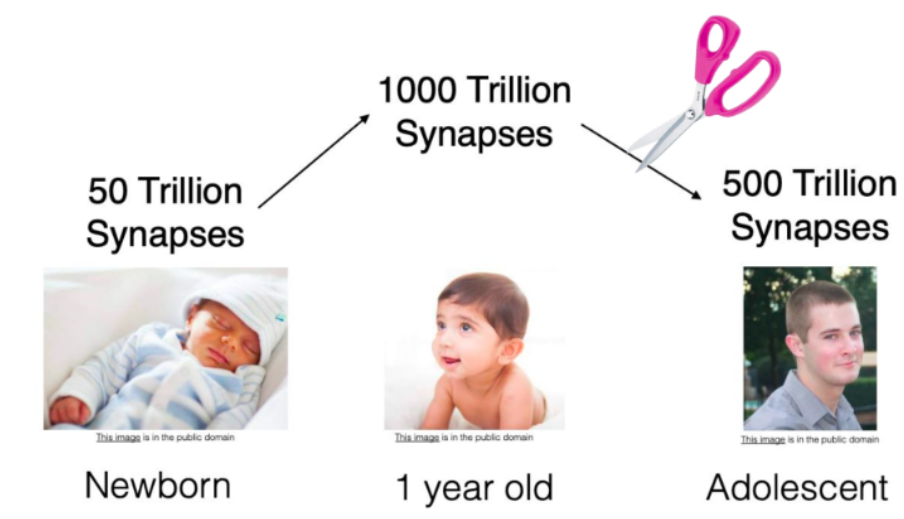
사람이 성장하면서 뉴런의 수가 감소하는 것과 유사하게 나타난다.
많은 뉴런 중 중요한 부분만 선별하여 크기를 줄임

파라미터의 값에 따라 가중치가 적용되기 때문에 pruning 결과 분포와 같이 0 주변의 웨이트들이 많이 사라진 것을 볼 수 있음

Pruning 결과
- iterative pruning을 적용한 모델은 약 90%의 웨이트를 날렸음에도 성능차이가 거의 없음
- pruning이 적용된 적은 수의 파라미터로 L1이나 L2 norm을 이용한 regularization(파라미터값 낮추기)을 수행하므로 좋은 성능을 유지할 수 있음
Q. Dropout과의 차이
- pruning : 파라미터 재사용 X
- dropout : 파라미터 재사용 O, inference과정에서는 모든 파라미터 사용 (앙상블과 유사한 효과를 가짐)
2. Quantization(양자화)
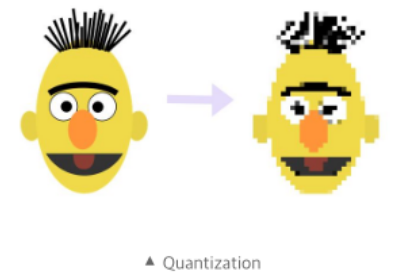
개요
학습된 딥러닝 모델이 weight값을 저장할 때 사용하는 비트의 수를 줄여서 모델 크기를 줄이는 방법

- 딥러닝에서는 숫자를 저장하고 연산할 때 주로 32개의 비트를 사용하는 32-bit floting point(or FP32)를 사용
- 만약 weight의 값이 더 적은 수의 비트로 표현해도 값의 차이가 작다면 더 적은 비트를 사용하는 편이 적은 메모리를 사용할 것임
- weight값을 저장할 때 FP16 또는 INT8로 표현 가능한 범위의 숫자로 변환한 뒤 해당 비트수만큼의 메모리에 저장하는 방법
- 더 적은 비트를 사용하기 때문에 모델의 메모리 사용량이 줄어드며, 모델을 사용해 추론할 때 동작시간을 단축할 수 있음
Q. quantization 종류
- PTQ: 말그대로 학습된 모델을 Quantization하는 것으로 속도가 빠른 대신 INT8 이하의 low precision에서 정확도가 떨어지는 문제가 있음
- QAT: 모델의 weight와 activation를 학습하는 과정에서 Quantization을 수행하여 속도가 느린 대신 INT8 이하 low precision에서 정확도를 보존할 수 있음
3. Distillation(Knowledge Distillation)
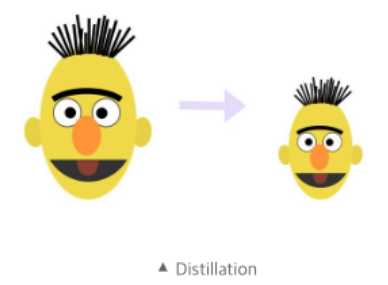
개요
거대한 모델로부터 얻은 지식을 더 작은 모델에 전달하는 과정으로, 작은 모델이 큰 모델과 유사한 성능을 내면서도 훨씬 적은 자원으로 동작할 수 있게 됨
어떤 모델을 사용하는 것이 적합할까?
- 복잡한 모델 T : 예측 정확도 99% + 예측 소요 시간 3시간
- 단순한 모델 S : 예측 정확도 90% + 예측 소요 시간 3분
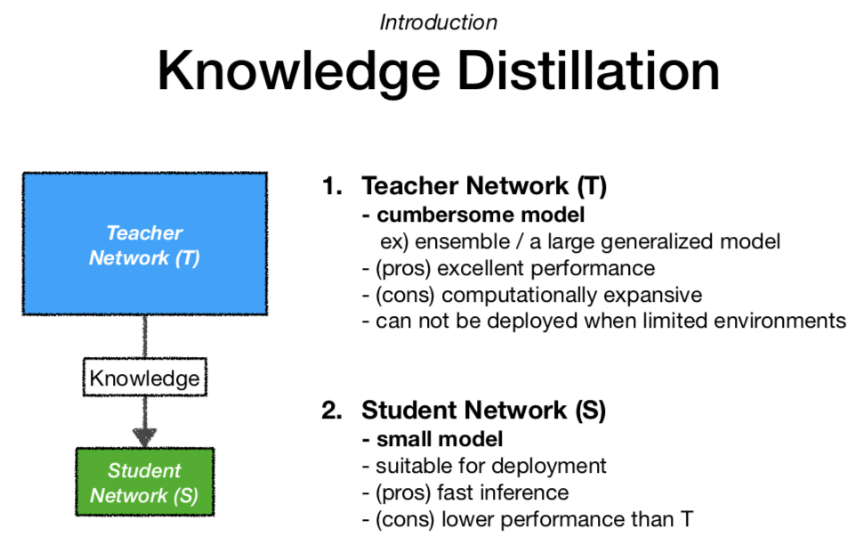
1) Soft label

- 신경망에서 이미지 분류 작업을 할 때, softmax 레이어는 각 클래스에 대한 확률을 출력
- 예측 클래스 외 다른 클래스의 확률도 중요한 정보를 제공함. 하지만, 이러한 값들은 softmax에 의해 너무 작아 모델에 반영하기 쉽지 않을 수 있음
- 이를 위해 출력값의 분포를 좀 더 soft하게 만들어 이 값들을 이용
2) distillation loss
- 앞에서 정의한 soft target은 결국 큰 모델(T)의 지식을 의미
- 큰 모델(T)을 학습을 시킨 후 작은 모델(S)을 손실함수를 통해 학습시킴
Q. Teacher model에서 어떤 지식을 가져갈건지?
- Response-Based Knowledge - 최종만 빼내는 경우
- Feature-Based Knowledge - 중간중간 layer의 결과를 빼내어 student에게 넘겨주는 경우
- Relation-Based Knowledge - 데이터 간의 정보(input layer), 여러 feature들간의 정보(hint layers), 출력 결과 간의 정보(output layer)처럼 특정 데이터 혹은 feature 간의 정보를 활용한 경우
Q. Student Model에 어떻게 전달할건지?
- Online-Distillation
- Offline-Distillation
- Self-Distillation
Q. 언어모델에서의 Knowledge Distillation 선행사례
- DistilBERT
- TinyBERT 4
- DistilGPT2
경량화의 장단점
- 전력 소모 및 비용 절감
- 직관적이며 안정적인 Output
- 일반화의 어려움
- 아직 성숙하지 않은 분야
관련 논문
1) Pruning
Learning both Weights and Connections for Efficient Neural Networks
Neural networks are both computationally intensive and memory intensive, making them difficult to deploy on embedded systems. Also, conventional networks fix the architecture before training starts; as a result, training cannot improve the architecture. To
arxiv.org
2) Quantization
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
Neural networks are both computationally intensive and memory intensive, making them difficult to deploy on embedded systems with limited hardware resources. To address this limitation, we introduce "deep compression", a three stage pipeline: pruning, trai
arxiv.org
3) Distilation
Distilling the Knowledge in a Neural Network
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome
arxiv.org
참고 자료
https://baeseongsu.github.io/posts/knowledge-distillation/
https://tilnote.io/pages/6480a73ee92fe5ef635f4d77
https://tech.scatterlab.co.kr/ml-model-optimize/
https://www.youtube.com/watch?v=NVNCPGWe5Ss
https://rasa.com/blog/compressing-bert-for-faster-prediction-2/#motivation